Introducing tidyusafec
Want to automate campaign finance data gathering from the Federal Election Commission? The FEC’s OpenFEC API is flexible from a developer’s perspective and cumbersome from an analyst’s. tidyusafec is a data retrieval R package that anticipates a desire to work with tidy campaign finance data directly in R.
Functions cover searching for elections, candidates, and committees and then getting more detailed data from their filings. While still very much in development, the most popular endpoints are covered and the package strategy reasonably stable. Functions can optionally return the raw results in list format. A tidy example below:
# Load R packages
library(tidyusafec)
library(tidyverse)
# Get Data
candidates <- search_candidates(office = 'H',
election_year = '2018',
district = '05',
state = 'VA',
unnest_committees = FALSE)
candidate_totals <- candidates %>%
get_candidate_totals()
# Wrangle Data
candidate_totals %>%
filter(type_of_funds %in% tidyusafec_filters$candidate_totals$type_of_funds$receipts_smallest_components,
cycle == '2018') %>%
arrange(-desc(amount)) %>%
mutate(type_of_funds = type_of_funds %>% str_replace_all('_',' ') %>% str_to_title()) %>%
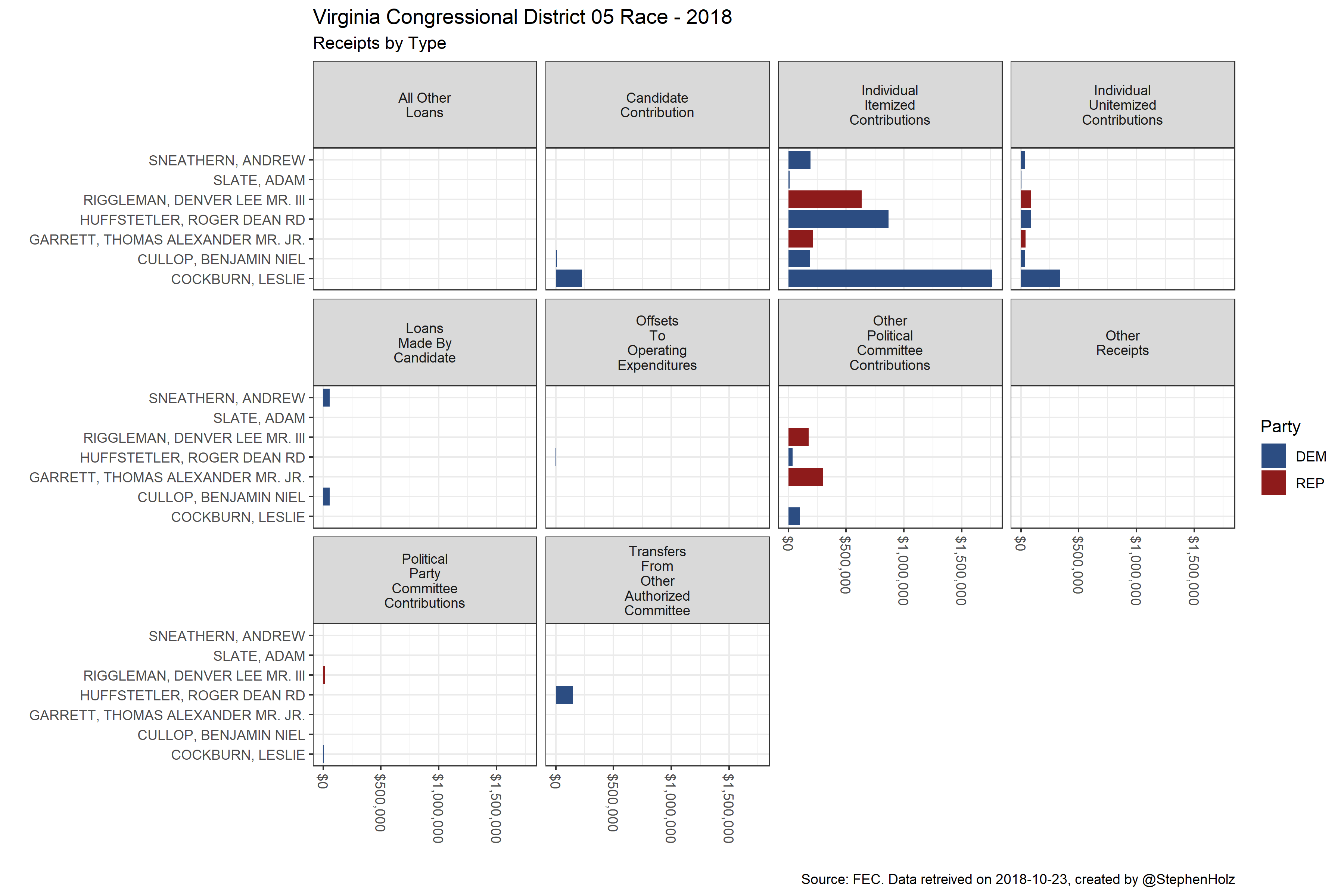
ggplot() + # Visualize Data
geom_bar(aes(x = forcats::as_factor(name), y = amount, fill = party), stat = 'identity') +
facet_wrap(~type_of_funds, labeller = label_wrap_gen(width = 10)) +
scale_y_continuous(labels = scales::dollar) +
coord_flip() +
theme_bw() +
scale_fill_manual(values = c('DEM' = '#2c4d82', 'REP' = '#8e1b1b', 'IND' = '#a3a3a3', 'GRE' = '#1c561d', 'LIB' = '#afac3d', 'NNE' = '#0A0A0A')) +
labs(
title = 'Virginia Congressional District 05 Race - 2018',
subtitle = 'Receipts by Type',
x = '',
y = '',
fill = 'Party',
caption = paste0('Source: FEC. Data retreived on ', Sys.Date(), ', created by @StephenHolz')
) +
theme(axis.text.x = element_text(angle = -90, hjust = 0, vjust = .5))
The package documentation site can help you get started :)